Lecture 8: Spatial regression
Source:vignettes/lecture08-spatial-regression.Rmd
lecture08-spatial-regression.RmdSpatial regression
Spatial autocorrelation is one specific aspect in statistical modeling. These features of spatial data create needs for special analytical techniques and should be considered every time a project involving geography (i.e., location) is attempted. In geography, the use of geospatial analyze has had a minor role in the research of regional development in Finland. Partly, this is due to the fact that these methods have been available for geographers for a little time. Methods require specific software and programming skills that are designed for specialist statisticians. However, the use of geospatial methods is advantageous, because traditional models, such as ordinary least squares regression, might give biased or in-efficient estimators for regression coefficients if spatial autocorrelation is omitted .
When to use regression analysis:
- Prediction of future observations
- Assessment of the effect of, or relationship between, explanatory variables on the response.
- General description of data structure
Assumptions to regression analysis:
- the ramdom error has mean zero
- the random error terms are uncorrelated and have a constant variance (homoskedastic)
- the random error term follows a normal distribution
Ordinary least squares regression (OLS-regression):
Linear regression analysis aims to identify and quantify the relationship between a dependent variable and a set of explanatory variables. In its most common form, ordinary least squares (OLS) regression can be written as:
or equivalently,
where
-
is the response variable,
-
represents the predictor variable(s),
-
are the unknown regression parameters, and
-
is the error term.
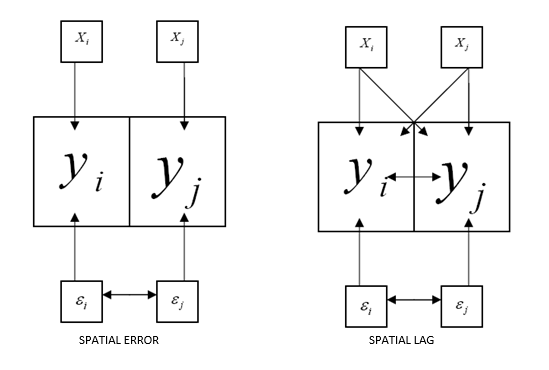
Spatial dependence
Spatial dependence exists when the value observed in a region depends on values observed in neighbouring regions. Previously, spatial dependence was examined using spatial autocorrelation statistics. In regression modelling, spatial dependence may occur either in the variables themselves or in the error terms.
Spatial lag model
In a spatial lag model, the dependent variable at location is influenced not only by the explanatory variables at , but also by values of the dependent variable at neighbouring locations . The spatial lag model is defined as:
where
-
is an
vector of observations of the dependent variable,
-
is the spatially lagged dependent variable based on the spatial weight
matrix
,
-
is an
matrix of explanatory variables,
-
is an
vector of error terms,
-
is the spatial autoregressive parameter, and
-
is a
vector of regression coefficients.
A statistically significant autoregressive coefficient indicates the presence of spatial spillovers, such as diffusion or copy‑cat effects.
Predicted values are calculated as
and residuals as
Spatial error model
In a spatial error model, spatial dependence exists in the error terms rather than directly in the dependent variable. The model is defined as:
with
where
-
is the spatial autoregressive coefficient for the error term,
-
is the spatially lagged error component, and
-
is an uncorrelated and homoskedastic error term.
Spatial error dependence is often interpreted as a nuisance process, reflecting spatial autocorrelation in omitted variables or measurement errors rather than substantive spatial interaction.
In this model, predicted values are calculated as
and residuals as
With spatial error in OLS-regression, the assumption of uncorrelated error terms is violated. As a result, the estimates are inefficient.
Exampe: Spatial Regression Analysis of Finnish Postal Code Areas
2. Downloading spatial data from Statistics Finland (WFS)
url <-list(hostname ="geo.stat.fi/geoserver/postialue/wfs",
scheme ="https",
query =list(service ="WFS",
version ="2.0.0",
request ="GetFeature",
typename ="postialue:pno_tilasto_2025",
outputFormat ="json"))%>%
setattr("class","url")
request <-build_url(url)
p25 <-st_read(request)## Reading layer `OGRGeoJSON' from data source
## `https://geo.stat.fi/geoserver/postialue/wfs/?service=WFS&version=2.0.0&request=GetFeature&typename=postialue%3Apno_tilasto_2025&outputFormat=json'
## using driver `GeoJSON'
## Simple feature collection with 3026 features and 113 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 83748.43 ymin: 6629044 xmax: 732907.7 ymax: 7776450
## Projected CRS: ETRS89 / TM35FIN(E,N)
url <-list(hostname ="geo.stat.fi/geoserver/postialue/wfs",
scheme ="https",
query =list(service ="WFS",
version ="2.0.0",
request ="GetFeature",
typename ="postialue:pno_tilasto_2016",
outputFormat ="json"))%>%
setattr("class","url")
request <-build_url(url)
p16 <-st_read(request)## Reading layer `OGRGeoJSON' from data source
## `https://geo.stat.fi/geoserver/postialue/wfs/?service=WFS&version=2.0.0&request=GetFeature&typename=postialue%3Apno_tilasto_2016&outputFormat=json'
## using driver `GeoJSON'
## Simple feature collection with 3036 features and 113 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 83748.43 ymin: 6629044 xmax: 732907.7 ymax: 7776450
## Projected CRS: ETRS89 / TM35FIN(E,N)3. Data preparation and merging
names(p16)## [1] "id" "gid" "posti_alue" "nimi" "namn"
## [6] "euref_x" "euref_y" "pinta_ala" "vuosi" "kunta"
## [11] "he_vakiy" "he_naiset" "he_miehet" "he_kika" "he_0_2"
## [16] "he_3_6" "he_7_12" "he_13_15" "he_16_17" "he_18_19"
## [21] "he_20_24" "he_25_29" "he_30_34" "he_35_39" "he_40_44"
## [26] "he_45_49" "he_50_54" "he_55_59" "he_60_64" "he_65_69"
## [31] "he_70_74" "he_75_79" "he_80_84" "he_85_" "ko_ika18y"
## [36] "ko_perus" "ko_koul" "ko_yliop" "ko_ammat" "ko_al_kork"
## [41] "ko_yl_kork" "hr_tuy" "hr_ktu" "hr_mtu" "hr_pi_tul"
## [46] "hr_ke_tul" "hr_hy_tul" "hr_ovy" "te_taly" "te_takk"
## [51] "te_as_valj" "te_nuor" "te_eil_np" "te_laps" "te_plap"
## [56] "te_aklap" "te_klap" "te_teini" "te_aik" "te_elak"
## [61] "te_omis_as" "te_vuok_as" "te_muu_as" "tr_kuty" "tr_ktu"
## [66] "tr_mtu" "tr_pi_tul" "tr_ke_tul" "tr_hy_tul" "tr_ovy"
## [71] "ra_ke" "ra_raky" "ra_muut" "ra_asrak" "ra_asunn"
## [76] "ra_as_kpa" "ra_pt_as" "ra_kt_as" "tp_tyopy" "tp_alku_a"
## [81] "tp_jalo_bf" "tp_palv_gu" "tp_a_maat" "tp_b_kaiv" "tp_c_teol"
## [86] "tp_d_ener" "tp_e_vesi" "tp_f_rake" "tp_g_kaup" "tp_h_kulj"
## [91] "tp_i_majo" "tp_j_info" "tp_k_raho" "tp_l_kiin" "tp_m_erik"
## [96] "tp_n_hall" "tp_o_julk" "tp_p_koul" "tp_q_terv" "tp_r_taid"
## [101] "tp_s_muup" "tp_t_koti" "tp_u_kans" "tp_x_tunt" "pt_vakiy"
## [106] "pt_tyovy" "pt_tyoll" "pt_tyott" "pt_tyovu" "pt_0_14"
## [111] "pt_opisk" "pt_elakel" "pt_muut" "geometry"
p16data<-p16[,c(3,79)]
p16data<-as.data.frame(p16data[,1:2])
colnames(p16data)<-c("posti_alue","tyopy16")
p16data<-as.data.frame(p16data[,1:2])
# merge 2016 and 2025 data
p25_data <- dplyr::right_join(x = p16data, y = p25, by=c("posti_alue" = "postinumeroalue"))
p25_data$tyopy16[is.na(p25_data$tyopy16)] <- 04. Creating change variables and indicators
# calculate changes
p25_data$tp_m22_16<-(p25_data$tp_tyopy-p25_data$tyopy16)
p25_data$tp_m22_16p<-((p25_data$tp_tyopy-p25_data$tyopy16)/p25_data$tyopy16)*100
p25_data$tyottom<-(p25_data$pt_tyott/p25_data$pt_tyoll)*100
p25_data$korkk<-(p25_data$ko_yl_kork/p25_data$ko_koul)*100
p25_data$alkut<-(p25_data$tp_alku_a/p25_data$tp_tyopy)*100
p25_data$elak<-(p25_data$te_elak/p25_data$te_taly)*100
p25_data$as_tih<-(p25_data$he_vakiy/(p25_data$pinta_ala/1000))5. Data cleaning
# create a new dataframe from part of the data
p25_data2<-p25_data[,c(1,14,67,78,118:122)]
# remove na and inf
p25_data3<-p25_data2 %>%
filter_all(all_vars(!is.infinite(.)))
p25_data4<-p25_data3 %>%
filter_all(all_vars(!is.na(.)))7. Spatial weights matrix (k‑nearest neighbours)
library(spdep)
data.coords<-st_centroid(st_geometry(data2), of_largest_polygon=TRUE) # Extracts the coordinates of each postcode area
p25_kn6<-knn2nb(knearneigh(data.coords,k=6,longlat = F)) # Returns a matrix with the indices of points belonging to the set of the k nearest neighbours of each other## Warning in knearneigh(data.coords, k = 6, longlat = F): dnearneigh: longlat
## argument overrides object
p25_kn6_w<-nb2listw(p25_kn6)Step 1: centroids
st_centroid(st_geometry(data2))Each postal code area:
- Has an irregular polygon
- Is reduced to one coordinate
Step 2: k‑nearest neighbors
knn2nb(knearneigh(..., k=6))Each area:
- Is connected to its 6 nearest neighbors
Step 3: weights list
nb2listw(...)Converts neighbors into a form usable by models.
Why k‑NN?
- Ensures every area has neighbors
- Avoids isolated rural polygons
- Common in regional and urban studies
8. Ordinary Least Squares (baseline model)
##
## Call:
## lm(formula = tyottom ~ korkk + alkut + elak + as_tih + he_kika.x +
## ra_as_kpa.y, data = data2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -49.855 -5.061 -1.280 3.452 73.922
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 39.674072 1.935040 20.503 < 2e-16 ***
## korkk 0.412926 0.018719 22.059 < 2e-16 ***
## alkut -0.032116 0.006403 -5.016 5.59e-07 ***
## elak 0.110485 0.014850 7.440 1.31e-13 ***
## as_tih -3.353124 0.172852 -19.399 < 2e-16 ***
## he_kika.x -0.170552 0.032218 -5.294 1.29e-07 ***
## ra_as_kpa.y -0.268296 0.011576 -23.177 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.472 on 2955 degrees of freedom
## Multiple R-squared: 0.3939, Adjusted R-squared: 0.3926
## F-statistic: 320 on 6 and 2955 DF, p-value: < 2.2e-16Purpose
This is your baseline, non‑spatial model.
You use it to:
- Understand relationships
- Generate residuals
- Test whether spatial models are needed
Key idea:
- OLS assumes independent observations — spatial data usually violates this.
9. Testing for spatial autocorrelation (Moran’s I)
moran1<-lm.morantest(model=m_ols, p25_kn6_w)
print(moran1)##
## Global Moran I for regression residuals
##
## data:
## model: lm(formula = tyottom ~ korkk + alkut + elak + as_tih + he_kika.x
## + ra_as_kpa.y, data = data2)
## weights: p25_kn6_w
##
## Moran I statistic standard deviate = 24.676, p-value < 2.2e-16
## alternative hypothesis: greater
## sample estimates:
## Observed Moran I Expectation Variance
## 2.458400e-01 -8.906051e-04 9.997406e-05What does this test?
- “Are the residuals spatially clustered?”
Result:
- Strong, significant spatial autocorrelation
Interpretation
OLS is misspecified because:
Nearby areas behave similarly
Independence assumption is violated
10. Lagrange Multiplier (LM) tests
#Next, we employ the LM tests for spatial lag (LMlag) and errors (LMerr)
LMtest1<-lm.RStests(m_ols, p25_kn6_w, zero.policy = T, test=c("RSlag", "RSerr"))
print(LMtest1)##
## Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
## dependence
##
## data:
## model: lm(formula = tyottom ~ korkk + alkut + elak + as_tih + he_kika.x
## + ra_as_kpa.y, data = data2)
## test weights: p25_kn6_w
##
## RSlag = 242.35, df = 1, p-value < 2.2e-16
##
##
## Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
## dependence
##
## data:
## model: lm(formula = tyottom ~ korkk + alkut + elak + as_tih + he_kika.x
## + ra_as_kpa.y, data = data2)
## test weights: p25_kn6_w
##
## RSerr = 600.46, df = 1, p-value < 2.2e-16
#The LMlag statistic is 264.07, whilst the LMerr statistic is 555,77. Both have p-values under .001, indicating that
#both the spatial lag and error models would be preferred over the OLS model.
LMtest2<-lm.RStests(m_ols, p25_kn6_w, zero.policy = T, test=c("adjRSlag", "adjRSerr"))
print(LMtest2)##
## Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
## dependence
##
## data:
## model: lm(formula = tyottom ~ korkk + alkut + elak + as_tih + he_kika.x
## + ra_as_kpa.y, data = data2)
## test weights: p25_kn6_w
##
## adjRSlag = 47.591, df = 1, p-value = 5.252e-12
##
##
## Rao's score (a.k.a Lagrange multiplier) diagnostics for spatial
## dependence
##
## data:
## model: lm(formula = tyottom ~ korkk + alkut + elak + as_tih + he_kika.x
## + ra_as_kpa.y, data = data2)
## test weights: p25_kn6_w
##
## adjRSerr = 405.71, df = 1, p-value < 2.2e-16
# both test statistics are significant which indicates that both models could be used.These answer:
Should spatial dependence be modeled as:
- Lag (spillovers)?
- Error (unobserved spatial factors)?
Key insight
- Both lag and error are significant
- Robust tests also significant
Interpretation
The standard LM tests (RSlag and RSerr) strongly reject the null hypothesis of no spatial dependence, indicating that the OLS model is misspecified. The robust LM tests (adjRSlag and adjRSerr) are also both significant, meaning that both spatial lag and spatial error specifications are plausible. Consequently, both SAR and SEM models are estimated.
The substantially larger robust error statistic suggests that spatial dependence is more likely to operate through the disturbance term rather than through direct spatial spillovers. This strongly hints that the spatial error model may fit better to our data.
11. Spatial Error Model (SEM)
library(spatialreg)
m2e <-errorsarlm(tyottom~ korkk+alkut+elak+as_tih+he_kika.x+ra_as_kpa.y, data=data2, p25_kn6_w, tol.solve=1.0e-30)
# call a summary to see the results
summary(m2e)##
## Call:errorsarlm(formula = tyottom ~ korkk + alkut + elak + as_tih +
## he_kika.x + ra_as_kpa.y, data = data2, listw = p25_kn6_w,
## tol.solve = 1e-30)
##
## Residuals:
## Min 1Q Median 3Q Max
## -47.05553 -4.46375 -0.94192 3.11477 60.89011
##
## Type: error
## Coefficients: (asymptotic standard errors)
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 57.0953845 1.9127290 29.8502 < 2.2e-16
## korkk 0.3388572 0.0172780 19.6121 < 2.2e-16
## alkut -0.0335142 0.0055793 -6.0069 1.892e-09
## elak 0.0480779 0.0125449 3.8325 0.0001269
## as_tih -0.6700999 0.2249769 -2.9785 0.0028964
## he_kika.x -0.5075504 0.0308752 -16.4388 < 2.2e-16
## ra_as_kpa.y -0.2500985 0.0105866 -23.6240 < 2.2e-16
##
## Lambda: 0.6882, LR test value: 665.04, p-value: < 2.22e-16
## Asymptotic standard error: 0.017061
## z-value: 40.337, p-value: < 2.22e-16
## Wald statistic: 1627.1, p-value: < 2.22e-16
##
## Log likelihood: -10526.41 for error model
## ML residual variance (sigma squared): 65.462, (sigma: 8.0908)
## Number of observations: 2962
## Number of parameters estimated: 9
## AIC: 21071, (AIC for lm: 21734)
hausman<-Hausman.test(m2e)
print(hausman)##
## Spatial Hausman test (asymptotic)
##
## data: NULL
## Hausman test = 74.076, df = 7, p-value = 2.208e-13What does SEM assume?
Spatial dependence comes from:
- Omitted variables
- Measurement error
- Region‑wide shocks
Why SEM often fits well
- Captures unobserved spatial processes
- Often removes residual autocorrelation
Moran I test confirms this.
##
## Monte-Carlo simulation of Moran I
##
## data: data2$residuals
## weights: p25_kn6_w
## number of simulations + 1: 1000
##
## statistic = -0.055526, observed rank = 1, p-value = 0.999
## alternative hypothesis: greater12. Spatial Lag Model (SLM)
m2lag <- lagsarlm(tyottom~ korkk+alkut+elak+as_tih+he_kika.x+ra_as_kpa.y, data=data2, p25_kn6_w, tol.solve=1.0e-30)
# call a summary to see the results
summary(m2lag)##
## Call:lagsarlm(formula = tyottom ~ korkk + alkut + elak + as_tih +
## he_kika.x + ra_as_kpa.y, data = data2, listw = p25_kn6_w,
## tol.solve = 1e-30)
##
## Residuals:
## Min 1Q Median 3Q Max
## -49.0059 -4.7046 -1.0960 3.2695 63.6558
##
## Type: lag
## Coefficients: (asymptotic standard errors)
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 36.5771818 1.9216355 19.0344 < 2.2e-16
## korkk 0.3938082 0.0178837 22.0205 < 2.2e-16
## alkut -0.0257826 0.0061369 -4.2012 2.655e-05
## elak 0.1049687 0.0142032 7.3905 1.463e-13
## as_tih -3.0787403 0.1651841 -18.6382 < 2.2e-16
## he_kika.x -0.2541911 0.0307810 -8.2580 2.220e-16
## ra_as_kpa.y -0.2417156 0.0111692 -21.6413 < 2.2e-16
##
## Rho: 0.34911, LR test value: 212.19, p-value: < 2.22e-16
## Asymptotic standard error: 0.02102
## z-value: 16.609, p-value: < 2.22e-16
## Wald statistic: 275.85, p-value: < 2.22e-16
##
## Log likelihood: -10752.84 for lag model
## ML residual variance (sigma squared): 81.807, (sigma: 9.0447)
## Number of observations: 2962
## Number of parameters estimated: 9
## AIC: 21524, (AIC for lm: 21734)
## LM test for residual autocorrelation
## test value: 230.78, p-value: < 2.22e-16##
## Monte-Carlo simulation of Moran I
##
## data: data2$residuals_lag
## weights: p25_kn6_w
## number of simulations + 1: 1000
##
## statistic = 0.098238, observed rank = 1000, p-value = 0.001
## alternative hypothesis: greaterWhat does SLM assume?
Unemployment in one area:
- directly affects nearby areas
- Spillover effects exist
Useful when:
- Policy diffusion exists
- Labor markets overlap strongly
Research example: Spatial double polarization of incomes in North Karelia 1996-2003
Lehtonen, Olli & Markku Tykkyläinen (2010). Tulotason spatiaalinen kaksoispolarisaatio Pohjois-Karjalassa 1996–2003 [Spatial double polarization of incomes in North Karelia, 1996–2003]. Terra 122: 2, 63–74.
Abstract: This study analyzes how a rapid period of growth of the Finnish economy affected taxable incomes by postcode area in a core-periphery setting. To investigate the extent of the spread of growth and the hypotheses of spatial polarization of incomes, we analyzed the change of both income gradients and surfaces in North Karelia in 1996 and 2003. Median taxable incomes of private individuals polarized between the regional growth center with its adjacent zone of influence and the declining rural periphery, as well as between the central district and its thriving adjacent settlement ring of 5–38 kilometers. A relative decline in incomes in natural-resource towns and sparsely-populated areas prevailed. Small towns and rural areas cannot successfully compete in conditions where economic growth is based on external and internal scale economies and urban-centered uni-nodal growth strategy. The geographically narrow spread effects challenges all involved actors to develop new technologies to overcome the friction of distance with less costs and to develop small-town and rural environments where industries not hooked on agglomeration economies can operate on a profitable basis.

In this example we make analysis in 6 steps:
- Step1: Importing shapefiles into R and constructing neighborhood sets
- Step2: Creating spatial weights matrices using neighborhood lists
- Step3: Using spatial weights matrices, run statistical tests of spatial autocorrelation
- Step4: Moving on to spatial regression
- Step5: Plotting the results
- Step6: Interpretation of the results
to be continue…